Multi-Class Classification on Variable Number of Subjects Using EEGNet
This post will summarize the results achieved using variable number of subjects and different parameters on EEGNet on THINGS-EEG dataset. Here, we will show how increasing the amount of data changes the network performance and possible inferences.
RSVP Paradigm
The RSVP paradigm, in which THINGS-EEG was constructed upon, is short for “Rapid Serial Visualization Paradigm”. This mode of collecting data is, making it simple, various images presented sequentially, with duration of (but can be different) 100 ms each image.
The subject is prompted a class and, after the presentation, says if the class was present in the images visualized. This makes possible for the dataset to be larger due to the reduction of sampling and stimulus time.
Nonetheless, during a LEARN meeting (the student research group I participate in) Victor Martins, who has significant understanding of neuroscience, asked questions about contamination of the data by other images. Even though the subject is looking for a certain class, the other images are also processed and, therefore, contaminates the stimuli captured.
This is a problem, since CNNs learns filters that comprises all the signal and, therefore, may generate activations for other classes that may merge on the signal processing. But, on the dense part of the network, it may be treated.
Although, the preprocessing of the data, reducing 1000 time samples to 100, even though reduces the processing power and removes artifacts, loses a lot of information, including those more relevant to the processing and classification by the network. Therefore, I may experiment on the unprocessed THINGS-EEG, removing artifacts without that much downsampling.
Multi-Subject Classification
Undertanding the paradigm, let us dive into the experiments done considering multiple subjects on the training data. In this case, there is still no cross classification, since the subjects on the training and testing data are the same.
First, I want to improve the performance on subjects that we trained on and then test for cross-subject classification.
Dropout
In the EEGNet paper, there is the parameter that controls the dropout rate. The paper recommends to use \(0.5\) when training (and inferring) on a single subject and \(0.25\) on multiple. Therefore, we tested it so check how this affects the model on the semantic data.
On the B dataset (as referenced on the first research log), using the first 5 classes and the first 4 subjects, we experimented the different dropout rates.
With the dropout set to \(0.5\) we got the results: 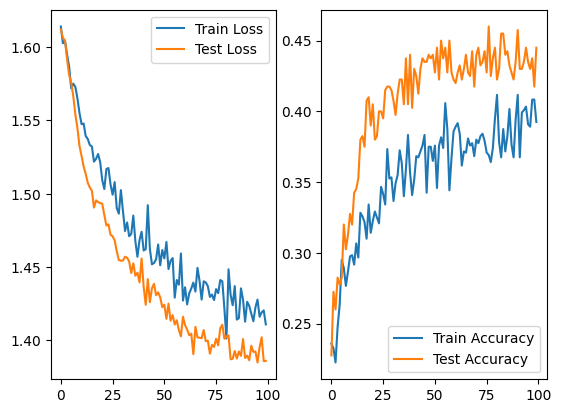
And we see that the losses are somewhat stable and the accuracy on the testing dataset is even better than on the training. This induces us to think that increasing the quantity of data we enhance our model, what is expected on a regular machine learning problem, but here may induce that different people may process the same semantic class on similar ways.
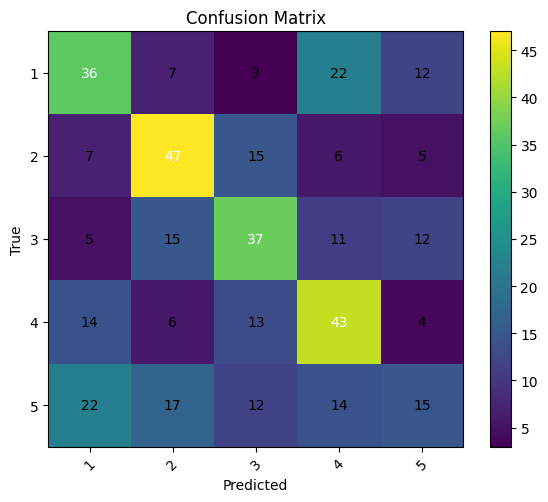
Now, we also see a main diagonal much more prominent than on the single-subject training explored on the last log, even though the is a great difficulty on classifying bananas correctly. With a dropout rate of \(0.25\), we got the results:
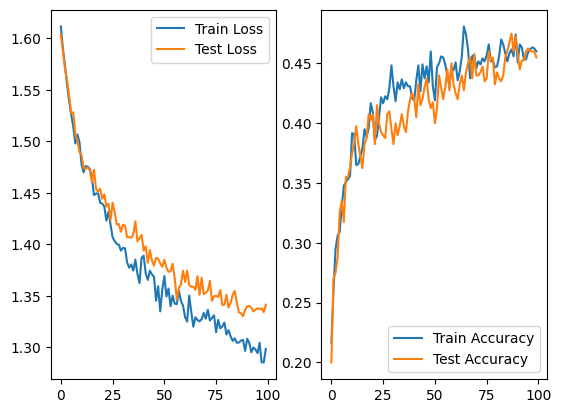
and we see that the loss achieves values lower than the other dropout rate and the accuracy os the both training and testing datasets are closer, also achieving higher values. This happens on most runs we tested, but is not a rule. Sometimes, the other dropout rate is better.
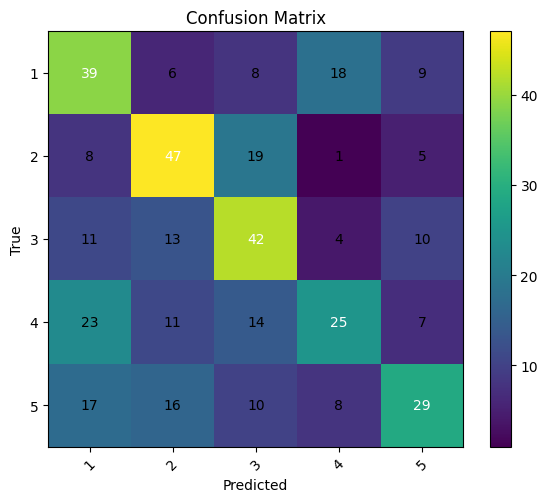
We also see a prominent main diagonal, what is expected since the accuracy is, on most training tuns, better than the other. We also can see that bananas are classified in a batter fashion than with the other dropout rates.
Following these results, we may adopt the \(0.25\) dropout rate to be standard on multi-subject classification.
Variable Number of Subjects
The main finding reported on this log is that there is some kind of alignment in the processing of semantic classes between different subjects.
Training the model on the first 5 classes and a variable number of subjects on the B subdataset of THINGS-EEG, from 1 to 10 subjects, we found that the accuracy grows with the number of subjects trained on.
This finding may not be a surprise in a regular machine learning paradigm, but considering that these are the processing of images with semantic information on different people, we may infer that the processing is similar across the subjects. This makes possible to use more people to make the model more accurate, reducing the problem of data scarcity mentioned on the last log.
The graphs can be found on the file “eegnet3ndexp.ipynb” in my github repo IC-EEG. The incresase of the accuracy, form 1 to 10 subjects, is of mere 12%, but let us look at the confusion matrices
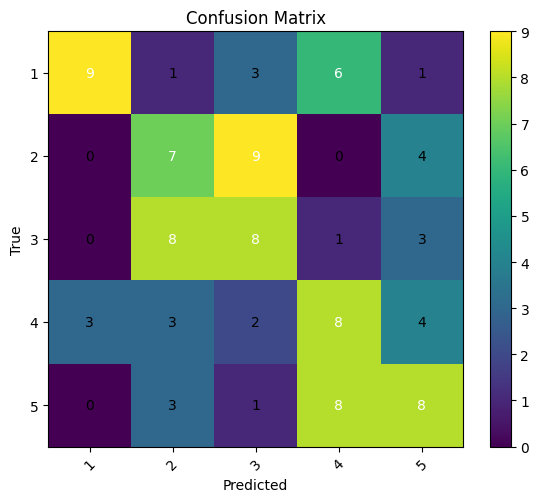
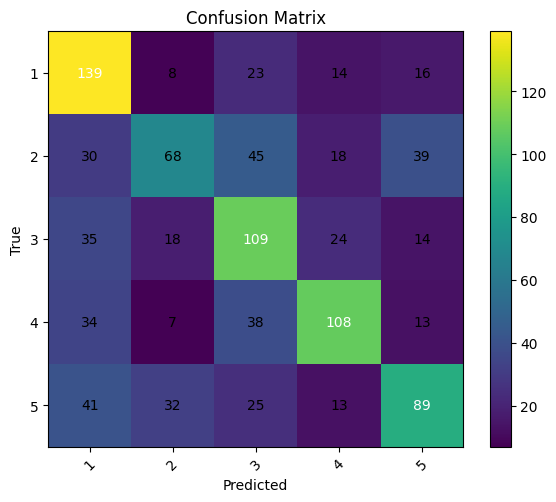
and it becomes clear how the model is improving its judgment since the main diagonal is clearly more apparent on the 10-subject data than on the single-subject.
We may now remember that the B dataset has only one stimuli per class and may consider that the findings may not happen again on a more variable dataset. Even though not completely sound, the doubt is valid and I tested how the model performed on the A dataset.
The same behavior is seen on the A dataset, even tough the difference on the accuracy is of about 5% and the confusion matrix are not as apparent as in the B dataset (due to the quantity of data), the inference made about the alignment of processing holds on the different datasets.